AN OBSCURE ENGINEER, BUILDING IN PUBLIC.
6 年软件开发经验,近 5 年深耕华为云 OpenStack 控制面。主导云原生化改造、性能调优与消息中间件治理。开源贡献者,prometheus/client_python 核心 PR 合并(73 轮 review,4 个月)。
背景
最近在用 Claude Code 重构个人网站,目标是做一个模拟 Linux 桌面环境的展示站。
这是一篇关于如何使用 AI 辅助开发的实践总结,记录了从设计到实现的完整流程。
核心挑战
- 窗口管理器 — 纯 Vanilla JS 实现拖拽、focus/blur 状态管理、动画
- 静态 + 动态 — Astro 静态构建,但需要客户端交互
- 内容管理 — Astro Content Collections 管理博客、电影、书籍数据
收获
AI 辅助开发最大的价值在于:帮你把”知道但懒得写”的样板代码快速落地。真正的创意决策还是得自己来。
背景
华为云 OpenStack 控制面最初依赖裸机部署,缺乏弹性扩缩容能力。我们团队负责将 30+ 个组件迁移到 K8s。
技术方案
指标采集
使用 Keystone 鉴权完成 Prometheus Exporter,遇到的核心问题是 prometheus/client_python 不支持 HTTPS/mTLS。
最终设计了 TLS 上下文切换方案,支持 TLS 与 mTLS 双模式,并向上游提交了 PR,经过 73 轮 review 后合并。
容器化改造
Keystone 和 wrap-trigger 的容器化改造涉及:
- 配置文件挂载(ConfigMap vs Secret)
- 健康检查端点设计
- 滚动升级策略
数据
改造完成后,节约估算超过 1000 人天的运维人力成本。
整体的时间规划
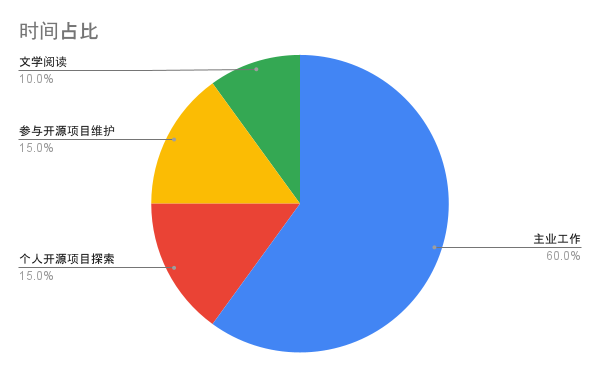
以周为单位,分割自己的时间安排
- 主业工作
- 个人开源项目探索
- 参与开源项目维护
- 文学阅读
个人开源项目探索
行动路线图
- Day 1-3:选择一个方向,用 100 行代码实现 MVP。
- Day 4-5:在 Reddit/Python 论坛发起讨论,收集反馈。
- Day 6-7:根据反馈迭代代码,发布 0.1.0 版到 PyPI。
- 持续运营:每两周发布一个版本,同步撰写技术博客解析设计思路。
向独立项目过渡的路线图
阶段 1:成为知名项目的核心贡献者(6-12 个月) 目标:在 2-3 个高活跃度项目(如 prometheus/client_python、requests)中进入贡献者排行榜 Top 10。 行动: 每月解决 1-2 个中等难度 Issue。 主动 Review 其他人的 PR,积累社区信任。
阶段 2:孵化实验性项目(1-2 个月) 目标:开发一个小型工具解决你在贡献过程中发现的痛点。 示例: 问题:prometheus_client 缺少与 logging 模块的深度集成。 项目:prometheus-logging-handler:将 Python 日志自动转为 Prometheus 指标。 差异化:支持自动统计 ERROR 日志频率、按日志来源(module)分维度统计。
阶段 3:推广与生态整合(持续迭代) 目标:让项目成为父生态的推荐工具(如进入 Prometheus 官方文档的”推荐客户端”列表)。 行动: 在父项目的社区会议/邮件列表中宣传你的工具。 提交 PR 将你的项目添加到父项目的生态页(如 Prometheus 生态)。
高中时我是很喜欢文学的,那也是我目前为止的文学巅峰,每个课间操我都会从下楼的队伍中偷溜出到一楼的图书馆里去看书,所以有幸进行了大量阅读。饶是如此,有位作者的书我却始终没有翻开过,那便是余华。在后来的十数年中,有非常多的机会,余华老师的书就在我的手边,我也鬼使神差的没有拜读。
最近又养成习惯读书,顺着微信读书总榜Top200读下来,第四本就是余华老师的《活着》,花了3个工作日的下班时间和1个周末的3个小时,便也读完了。有些感想,便写下这篇读后感记录一番。
倒叙来讲,我读的版本最后附着很多报社对该书的评价,落款好部分都是一九九八年了,包括书的结尾落款也是一个”一九九二年一月三日”,令我有所感触的是突然意识到早在我未出生时,便有很多传世之作已然落成,甚至该说此生我能有幸拜读的巨著其实都早已写就并出版多年,躺在不知道哪里,等着我能走到它身边去翻开它。这个认知实在令我太过惊喜了,原来我想要认知的世界,我所有的迷茫,绝大多数早已有人想明白并以各种形式把自己的思想记录了下来。我所要做的就是在书海里找到它,这与花费自己有限的一生去探索来说,实在是过于简单。
书往前翻,是福贵这充满苦难的一生,而且是究极的苦难——死亡,与这般苦难相比,即使是书中描写没有粮食吃的恐怖景象都显得好像是幸福的日子。于福贵经历而言,我因为缺乏工作经验而感到的惶恐与压力,因为缺乏人生经验而感到的矛盾与痛苦,实在是显得有种小孩子过家家的幼稚感。我所经历的事情,所面临的困难,其实即使是以最差的结果去估计,也不过是丢脸、被批评,甚至连挨打挨饿都绝无可能。所以我的担惊受怕完全是多余的,努力去做好就行,结果不好也没关系。
背景
在公司的时候,有很多调试环境部署有K8S集群供开发自验证,
但在家参与一些开源项目的时候,因为无法使用公司环境,导致缺少可以自验证的环境。
以前一般使用MiniKube或Docker部署K8S集群等方式构建测试环境,
但缺点是对机器的要求比较高,我的17年8G运行内存的Mac只能是堪堪运行起集群,
再要在上面做一些调试,开个IDE,开个浏览器等,十分费劲。
趋势
升级机器配置,我也有过这个想法,但不免几年就需要升级一次,费钱费时间,且机器95%以上的时间都是闲置的,并不划算。
所以利用付费的云化资源+轻量的终端进行开发工作,越来越成为我近年来的一种趋势。
本文也是基于这一种思想构建的一种调试方法,供君参考。
更进一步
单纯的云化资源并不能很好的控制成本,借鉴企业的的做法,弹性伸缩才是降低成本的要点。
所以我们在使用云化资源的时候也要贯彻这一种做法,
尤其在需要使用K8S集群这类资源开销更大的业务时,
使用Terraform在测试时自动化创建出基础设施,是我们应该提倡的。
以Provider为例
上周在工作中遇到一个Kubernetes Provider的社区Bug,因为公司的业务版本发布在即,所以优先采用打补丁的方式完成修复。
但计划在业余时间帮助社区修复该Bug,修复时发现缺少自验证的环境,于是开始探索下面使用AWS的EKS构建测试环境的方法。
登录AWS控制台
登录AWS的EKS服务,本文以美国(俄亥俄州)为例
安装Terraform
参考Terraform的Install教程,在AWS临时终端中安装Terraform
sudo yum install -y yum-utils shadow-utils
sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo
sudo yum -y install terraform
部署EKS集群
参考Terraform的部署EKS集群教程,通过AWS终端部署EKS集群
初始化工作空间
git clone https://github.com/hashicorp-education/learn-terraform-provision-eks-cluster
cd learn-terraform-provision-eks-cluster
terraform init
部署集群
terraform apply -auto-approve
预计花费10分钟完成集群部署,部署后可以在ESK集群管理页面看到该集群
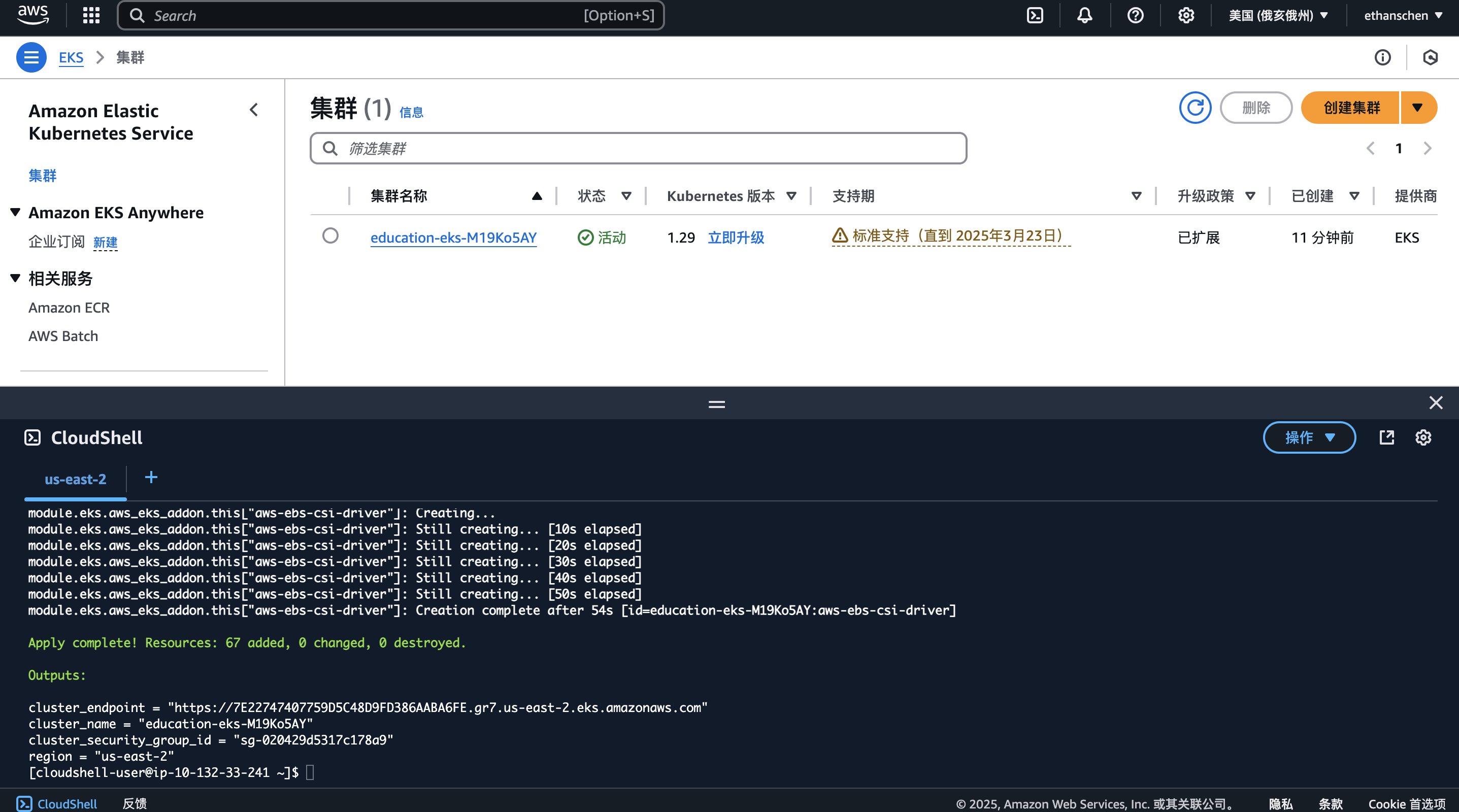
验证集群功能
配置kubectl
aws eks --region $(terraform output -raw region) update-kubeconfig --name $(terraform output -raw cluster_name)
查看集群信息
kubectl cluster-info
查看node信息
kubectl get nodes
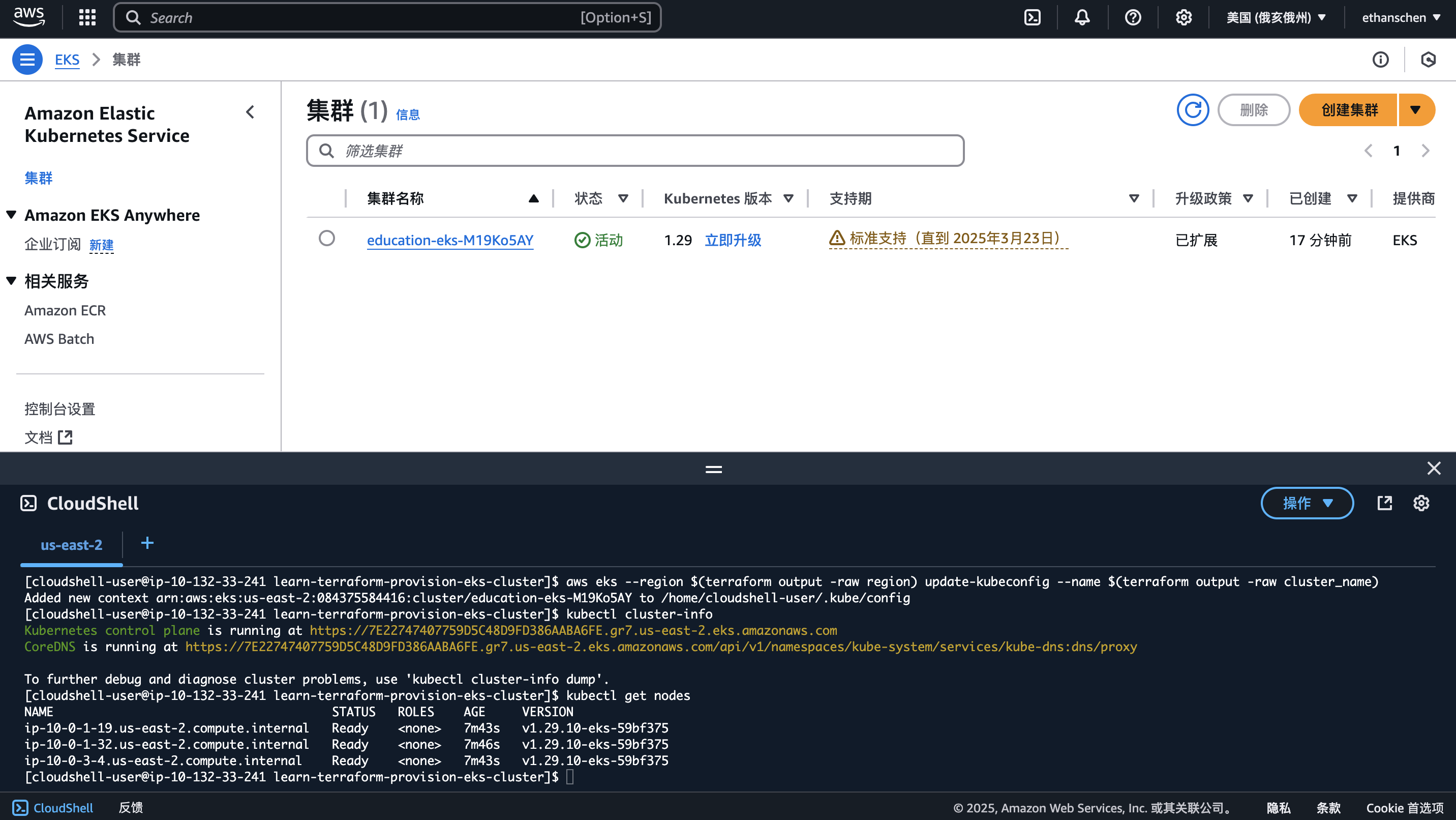
部署Deployment资源
参考Terraform的管理K8S资源,通过Terraform部署测试服务到集群
创建工作目录,编辑kubernetes.tf文件
cd ~
mkdir learn-terraform-deploy-nginx-kubernetes
cd learn-terraform-deploy-nginx-kubernetes
vim kubernetes.tf
初始化工作目录
terraform init
修改kubernetes.tf,增加Deployment资源后Apply
vim kubernetes.tf
terraform apply -auto-approve
查看Deployment资源
kubectl get deployments
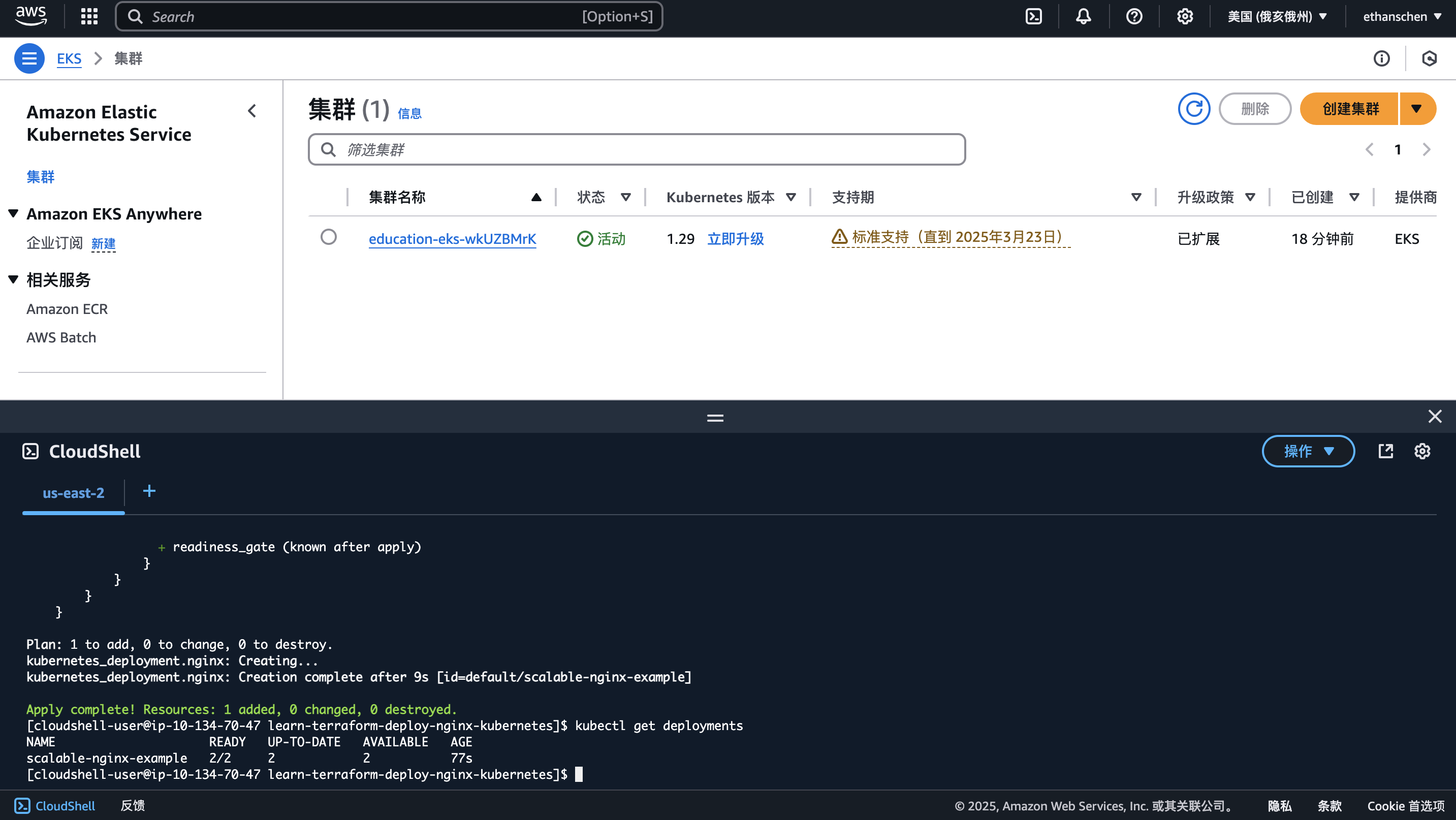
去部署Deployment资源
cd ~/learn-terraform-deploy-nginx-kubernetes
terraform destroy -auto-approve
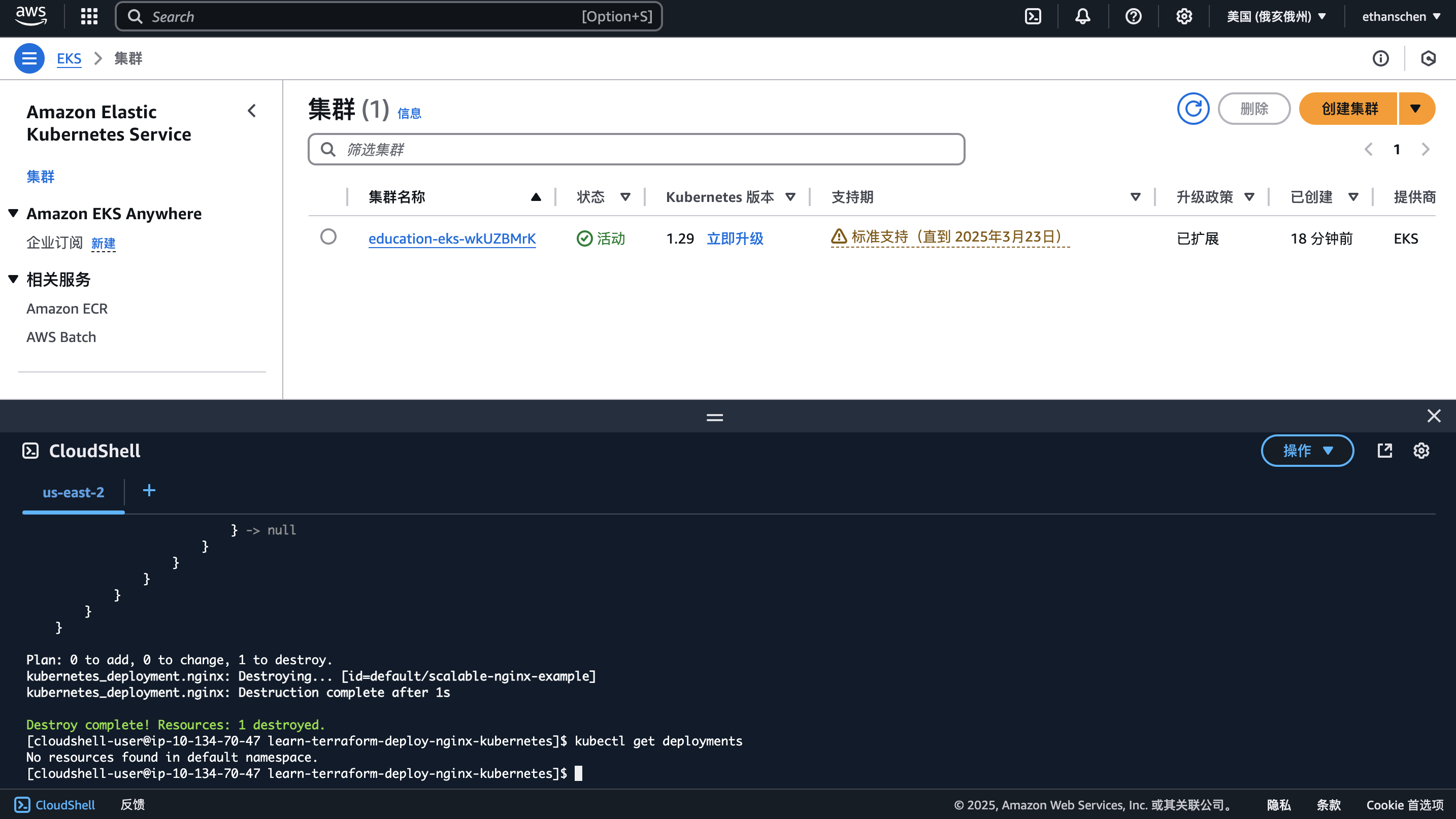
调试Provider
参考Kubernetes Provider项目的贡献指南
安装Go
brew install go@1.22
克隆Provider项目
Fork Provider项目到自己的仓库下,再克隆到本地
git clone https://github.com/<YOUR-USERNAME>/terraform-provider-kubernetes.git
cd terraform-provider-kubernetes
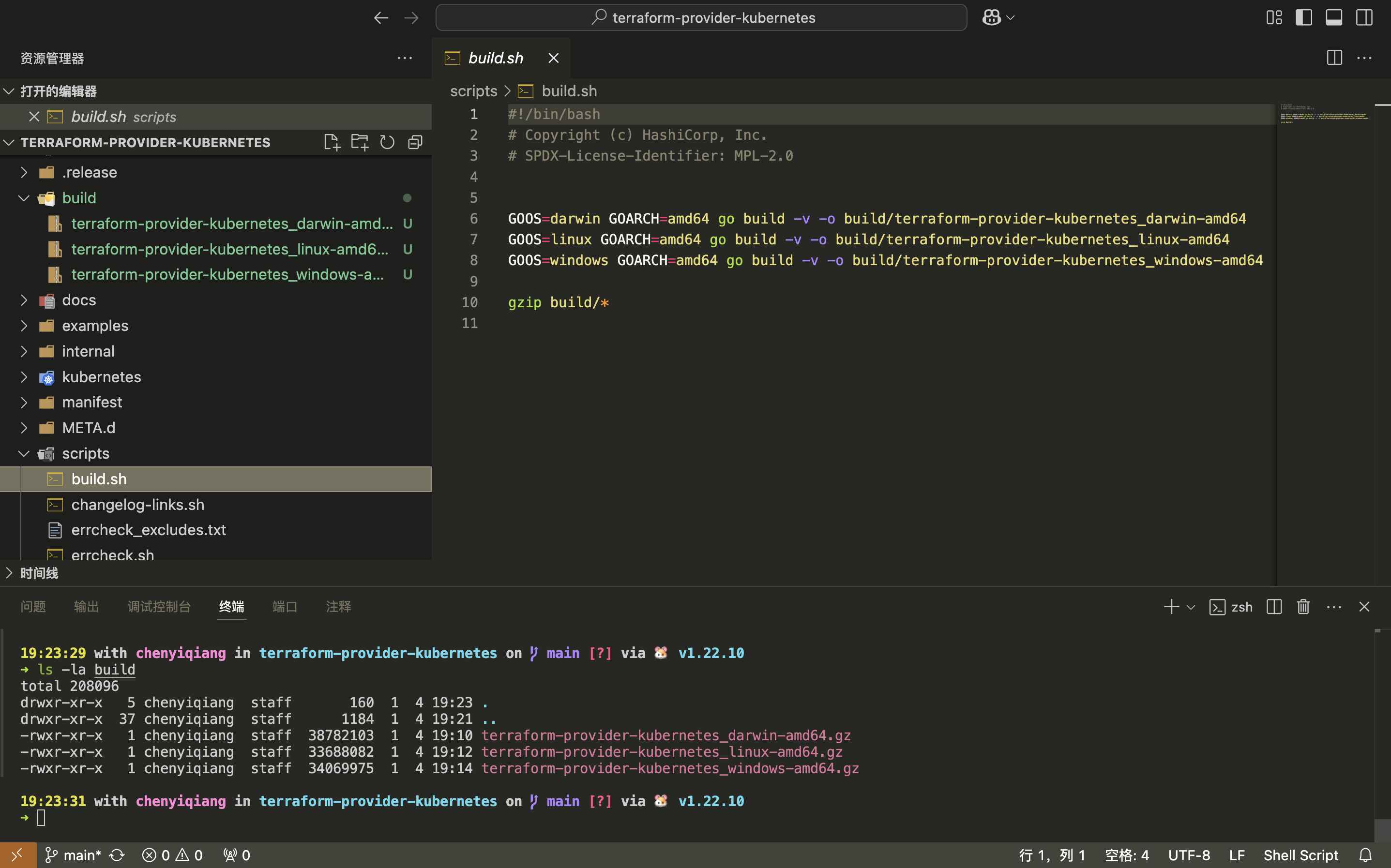
修改代码
即修改terraform-provider-kubernetes代码
编译Provider
bash scripts/build.sh
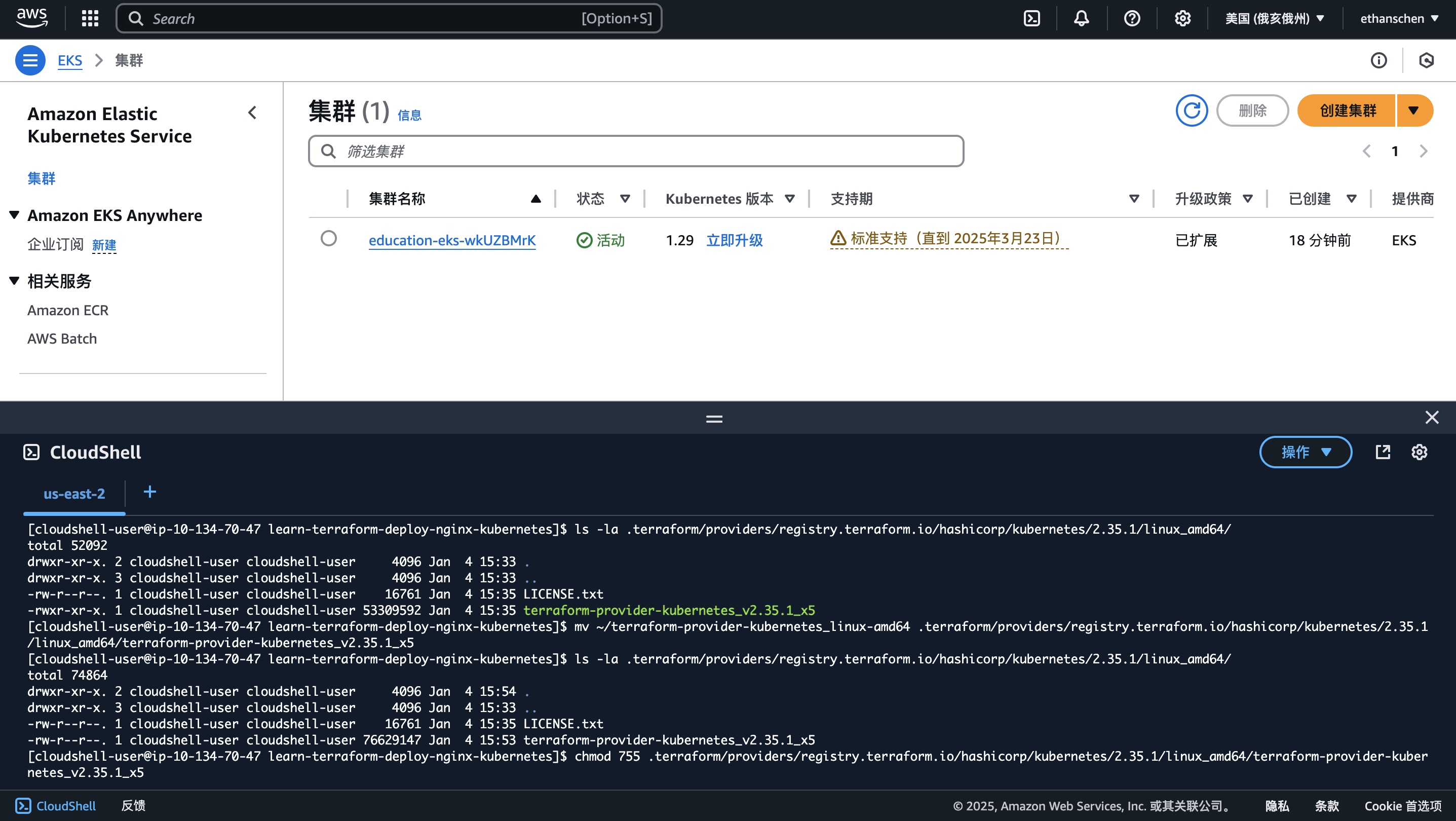
替换二进制文件
将编译好的Provider上传到AWS终端,替换原二进制文件
验证Provider修改
执行可以验证到修改的操作,例如再次部署Deployment资源
去部署EKS集群
验证完毕,别忘了销毁集群,因为它时刻都在计费!
cd ~/learn-terraform-provision-eks-cluster
terraform destroy -auto-approve
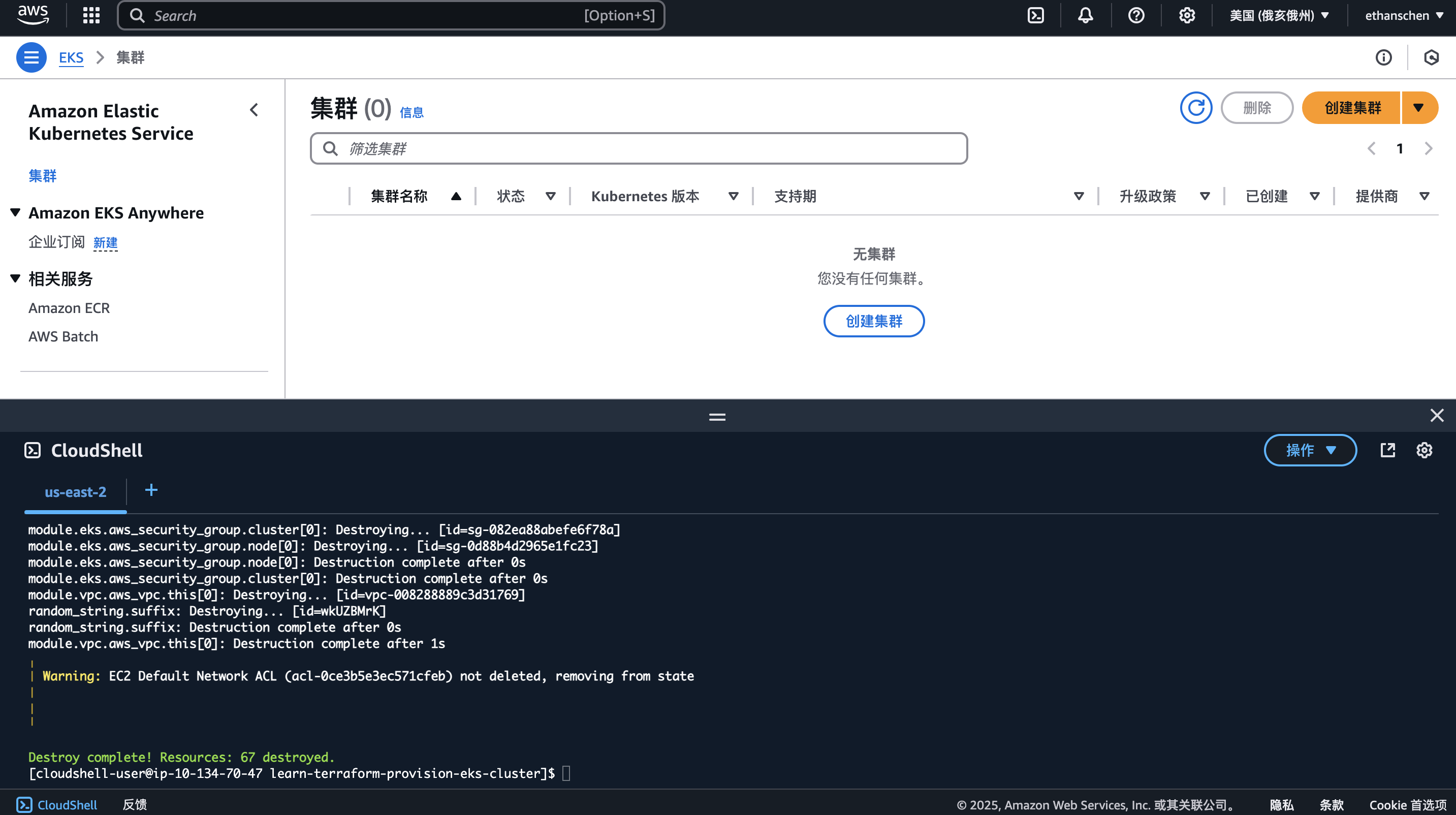
总结
到此,本文介绍的方法就讲完了,欢迎各位一试~
书接上回,
继续写下自己的思考。
工作记录
先是工作记录,虽说24.12.0版本已经发布,
但我仍在一个不走一般版本节奏的项目里,
且10号就是首次联调的时间,在那之前需要解决的问题还有很多,
今天一天都在带着几个项目组里的同事与其他部门同事对齐问题,修复并验证问题。
等反应过来,就已经晚上8点30分,到下班时间了。
诚然,解决问题的时候使用番茄钟可以提高效率,
但我也确实在研究SDI卡PXE的时候钻牛角尖了,浪费太多时间才开始寻求相关业务同事的帮助。
996怪圈
再着继续讲下【996怪圈】,
我第一次接触到996这个名次就是在鼎鼎大名的 996.icu 网站大火的时候,
不出意外,这个网站也被墙了。
当时对996的看法也就纯当茶余饭后的同事谈资而已,
没有想过这种工作制度对自己有何影响,
也可能是当时我并没有进入到这样的一种工作制中,
不像现在,我整已经在这种工作制中3年多。
再次看到聊这个内容就是在编程随想的博文了,其中提到
大多数人都知道——加班意味着业余时间减少。业余时间减少也就意味着:你更加没有时间去自学,去提升自己的能力。
如果你的能力得不到提升,你在人力市场上的【议价能力/谈判筹码】也就得不到提升。然后你就不得不继续接受这种变态的工作时间。
俺把这称之为【996怪圈】——它是一个恶性循环(恶性正反馈),你陷入其中,并越来越无法自拔。
我十分赞同,也是第一次理性的审视我正在从事的工作对我的影响,
此前虽然模糊间一直有类似的想法,但并未真正的提出来并认真思考过。
也提到
首先,大部分人的工作都【不是】自己的兴趣所在。 其次,超长的工作时间,使得你必须长时间面对自己不感兴趣的工作内容,所以你必须动用”自控力”以完成自己的工作。 最后,当你忙碌了一天,终于回家的时候,很可能你的自控力已消耗殆尽。 结论就是:如果你的工作不是你的兴趣所在,长时间加班之后,回到家里,你很难再有动力去学习其它新技能。
我不能更赞同了,其实我可以完全可以接受超长时间的工作,
前提是我觉得这个很有意义,我感兴趣,
如果是这样,我想我应该会干到很晚,睡几个小时,
睡醒立马继续干,这也是我的理想状态 ——热情工作时全身心投入,阶段性休息时完全放松。
借今天的思考,
把结论写在个人网站首页,
尽早推演出跳出【996怪圈】的术,然后证道,走向理想工作~
早上
元旦,出门去取前几日送到4S店维修漆面的车。
刚出小区,看着路旁的小河,开始感叹年复一年时光流逝。
突的回想,实际上记不起来太多,只能模糊的感觉到自己在成长,
但也怀疑是否很多时间都因为忘记目标而被浪费。
跳出来想,也许看似浪费时间的时常记录和反思才是捷径,
因为这种记录能给予后来阅读的自己力量,令”其”道心不变,坚定地走下去。
中午
中午,在浙江图书馆门口遇到传统的爆米花,第一次见,来了兴趣拍了几张。

接下来的八小时
接下来的八个多小时,沉浸在这个我初次探访的图书馆的自修室,
内容是由一开始的”为hashicorp/terraform-provider-kubernetes开源项目修复一个上周工作中遇到的Bug”
到”给hashicorp/terraform-provider-kubernetes开源项目提该Bug的Issue并与社区成员确认修复方案是否可行”
再到”使用AWS的EKS搭建terraform-provider-kubernetes测试环境”,
我的开发工作就是这样,
总是一直入栈,然后再一步步出栈,才能完成。
但很不幸,之前没有记录的时候,对于开源这类没有外部Push的任务,
往往在经历一周的工作后就不知道被我忘到哪里去了。
到家后复盘,其实任务本身倒是其次,
而我对待这些任务的态度则更为重要。
反思
今天反思后想到的几个点:
- 需要延长每日的工作时间,不为别的,而是需要在本职工作外有时间投入其它,避免陷入”996”怪圈
- 本职工作占据的时间太长,且很多时候压力太大,经常让我陷于其中而忘了职业生涯这盘大棋,这需要每日警醒
- 记录本身很耗费时间,尤其在刚开始做这个事情的时候,但时间一长不经能让我阶段性复盘调整,也是我以后向上最扎实的土壤
暂且记这几点。

中国人的收入到底有多高
中国有多少穷人?
总理李克强给了一个算得上官方权威的回答:中国有「6亿中低收入及以下人群,他们平均每个月的收入也就1000元左右」。
如上文分析,【家庭人均可支配】的说法让我们高估【不足1000元】的贫困程度,实际上这可能是我们周边非常普通的一个外出务工家庭的收入水平。
月税后挣到5000元以上(包括奖金),就超过了全国 80% 的工薪族。税后工资过万,超过 97.5%。
How law enforcement gets around your smartphone’s encryption
When an iPhone has been off and boots up, all the data is in a state Apple calls 【Complete Protection】. Once you’ve unlocked your phone that first time after reboot, though, a lot of data moves into a different mode—Apple calls it “Protected Until First User Authentication”, but researchers often simply call it 【After First Unlock】(AFU).
如上文分析,政府执法机构破解手机比多数人想象中的更容易。开机第一次解锁之后,全盘加密的密钥就会位于内存中。此时只要能利用某种系统漏洞拿到内存中的密钥,就可以解密手机数据。相比之下,关机状态下破解难度大得多。
博弈论【换位思考】
需要站在”对手”的角度进行思考,才能看清局面,从而更好地选择自己的策略。
华为鸿蒙争议
华为高管的辩解,属于”偷换概念”(稻草人谬误)。 把”鸿蒙使用AOSP代码”偷换为”鸿蒙使用谷歌代码”,再针对后一个命题进行反驳——这是典型的稻草人谬误。
阅读节选
我是觉得人一定要有自己的基本盘,这非常重要。比如我现在问很多人,以后还有什么目标、理想吗?他们都说没有。我是一直有的,甚至知道自己以后十年、二十年、三十年、四十年的目标。始终有一个目标,也许你到不了,但是一直在路上,你在这个过程中是有满足感的,所以我觉得,能在新的价值体系里找到一个新的目标去追求,非常重要。这个目标必须相对具象,而且真的和你对自己的情感认同、价值认同有关联。 有时也许你不知道自己的目标在哪儿,但是只要你完成眼前的这个目标,到达一个更高的平台,就能看到新的东西,那一刻,你就会突然发现自己要的是什么。 我们要有一个成长的目标和方向,它不是一个轻浮的点,而是用它构筑起来一个你愿意活在其中的系统,这也是我曾经所说的心理张力的来源。我们要在自己定义的价值体系里,体验到不断积累、丰富、前进、变化的感觉,只要这种体验能贯穿在生命里,无论你做什么,你都会在不可避免的生命之苦之外,体验到活着的感觉,并且想要好好活着。
—— 节选自《多谈谈问题》
当精神分析告诉我,我的原生家庭决定了我的宿命,我就非常生气。对我来说,我作为一个学过哲学的人,最大的荣誉就是捍卫自由意志。我所有作品都会涉及人类有自由意志这样一个基本观念。一个思考哲学问题的人,如果摒弃了自由意志,对我来说是不可想象的。**我认为一个人文主义者应该坚定地同机械主义、决定论、宿命论做最持久的斗争,因为这不仅关乎自由意志,更关乎人类的道德。决定论就是一个悖论,它会架空人类的道德。自由意志是不可知的,它是神秘的、超验的。**为什么聊弗洛伊德的观念?因为我觉得这是僭越人类的自由意志。从这个角度来说,我去读阿德勒,他的作品能给我们带来更宏大、更有希望的图景,因为你的选择决定了你的当下,决定了你的未来。
—— 节选自《多谈谈问题》
我们犯的第一个错误是选错了试图改变的事情。为了更好地理解我的意思,你可以考虑把改变发生的进程分为三个层次,就像洋葱一样。 第一层是改变你的结果。这个层次事关改变你的结果:减肥、出版书籍、赢得冠军。你设定的大多数目标与这个层次的改变相关。 第二层是改变你的过程。这一层次涉及改变你的习惯和体系:定时去健身房锻炼、定期整理你的办公桌以提高工作效率,以及按时练习冥想。你养成的大多数习惯与这一层次有关。 第三层是改变你的身份。这一层有关改变你的信念:你的世界观、你的自我形象,以及你对自己和他人所做的判断。你持有的大多数信念、假设和偏见与这个层次相关。 结果意味着你得到了什么,过程意味着你做了什么,身份则关系到你的信念。当谈到培养持久习惯,以及创设改进1%的体系时,问题不在于这层比那层”更好”或”更差”。所有层级的变化都各有用处,关键是改变的方向。 许多人开始改变自己的习惯时,把注意力集中在自己想要达到的目标上。这会导致他们养成基于最终结果的习惯。正确的做法是培养基于自己身份的习惯。借助于这种方式,我们的着眼点是我们希望成为什么样的人。 真正的行为上的改变是身份的改变。
—— 节选自《原子习惯》(中文版)
背景
上周更新了一篇文章《一致性Hash算法与虚拟节点》,阅读和收藏人数挺多的。
今天有朋友问了我一个问题,虚拟节点如何保证均匀分布?
我不假思索的回答,
不需要保证虚拟节点的均匀分布,
虚拟节点用以保证相对的均匀靠得是量变产生质变,
就像我文末提到的,在实际场景中,虚拟节点的个数只有3个是远远不够的。
例如Dubbo中用到一致性hash算法时,默认的虚拟节点个数是160个,
假设我们有四个服务节点需要创建虚拟节点,那就会有 4 * 160 = 640 个虚拟节点,
在这样大量的基数下,必然他们的分布就会呈一种相对均匀的状态。

回答完我感觉很满意,不愧是我!
可转念一想,再想,三想,
好像不是这么一回事,
别说是有640个节点了,就算有6400个,64000个节点又如何呢?
在极小极小的概率下,如果hash算法不能保证映射的均匀性,
他们依然可能落在十分聚集的一小块区域中。
反推一下,既然一致性hash算法作为一个成熟并拥有很多应用场景的算法,
不可能如此不严谨,所以hash算法本身应该是可以保证映射的一致性的。
东查西查,终于有了答案。
一个合格的散列函数包含三个特征:
- 单向性:容易计算输入的散列结果,但是从散列结果无法倒推出输入;
- 抗冲突性:很难找到两个不同的输入散列结果相同;
- 映射分布均匀性和差分分布均匀性:散列结果中 bit 位上的 0 和 1 的数量应当大致相等;改变输入内容的 1 个 bit 信息会导致散列结果一半以上的 bit 位变化(雪崩效应)。
Dubbo 仓库 ConsistentHashLoadBalance 类的关键代码:
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = Bytes.getMD5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
总结
在Dubbo的源码中,实现一致性hash算法时,用于计算副本位置的定位算法实际上每个位置只需要 MD5 值的四分之一。而合格的散列函数保证了映射分布的均匀性(雪崩效应),即虚拟节点的均匀分布。
缘起
今天我们来说说”一致性Hash”算法,以及虚拟节点。
这并不是一个难理解的概念,希望一篇文章下来,你能完全吃透。
在网站系统发展初期,前辈工程师探索出了数据库这一系统核心组件,
数据的持久化被与系统本身解耦开,独立发展且愈加可靠。
时间往后推移,随着互联网的普及,一个系统需要承载的用户数量指数级增长,
开发者不得不横向扩展服务器,通过负载均衡技术,使用户分散到各个服务器上。
随着服务器的增多,可靠的数据库系统也不堪重负,
开发者不得不将数据库中的数据通过”分库分表”技术,切分到不同的数据库中,
减轻单一数据库系统的压力。
那么问题来了,如何知道我们需要的数据在哪个数据库中?
没错。hash!
正如我们在 HashMap 中做的一样,对参数取 hash 值,再对 hash 值取模,
就可以既均匀切分存储数据,又知道数据在哪个库中。
简单hash
举个例子,现在有A,B,C,D共4个库,和参数为1,2,3……9,10共10个数据。
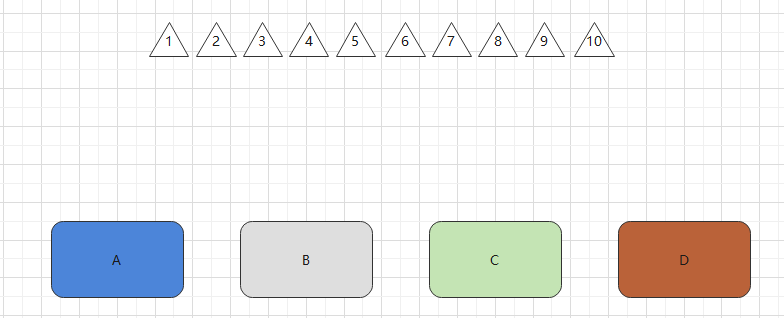
我们简化hash算法为乘以1,
即 (1*1)%4=1,参数为1的数据落在A库中。
即 (2*1)%4=2,参数为2的数据落在B库中。
即 (3*1)%4=3,参数为3的数据落在C库中。
即 (4*1)%4=0,参数为4的数据落在D库中。
……
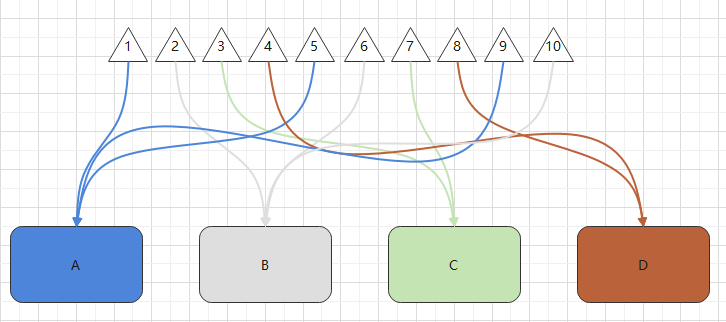
嗯!我很满意,一切井然有序。
当系统需要参数为2的数据时,只需要通过定位算法 (2*1)%4=2 便知道数据存在B库中。
当系统需要参数为9的数据时,只需要通过定位算法 (9*1)%4=1 便知道数据存在A库中。
可好景不长,正当系统稳定健康运行的时候,
B库不知道出现什么问题,失去了连接,系统中只剩下A,C,D共3个库。
这可真糟糕,但是我们还不知道会发生什么事情,对系统的影响有多大。
让我们先把目光聚集到局部上面来分析一下,
参数为2,6和10的数据存在B库上,影响应该是最大的,
如果现在系统需要参数为2的数据,那么它会通过定位算法 (2*1)%3=2 找到C库上。
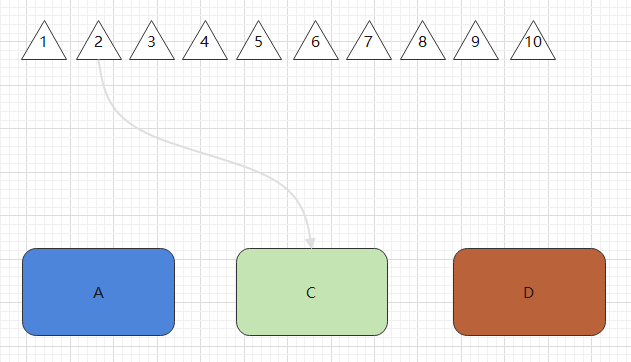
但很遗憾,C上并没有存储参数为2的数据。
值得庆幸的是,原来数据是有副本的,失去连接的B库数据并没有丢失,而是在一个更大的主库中,
只要给系统一些时间,主库中对应B库的数据,就会根据定位算法被重新分配到A,C,D库中。
分配如下,
即 (2*1)%3=2,参数为2的数据落在C库中。
即 (6*1)%3=0,参数为6的数据落在D库中。
即 (10*1)%3=1,参数为10的数据落在A库中。
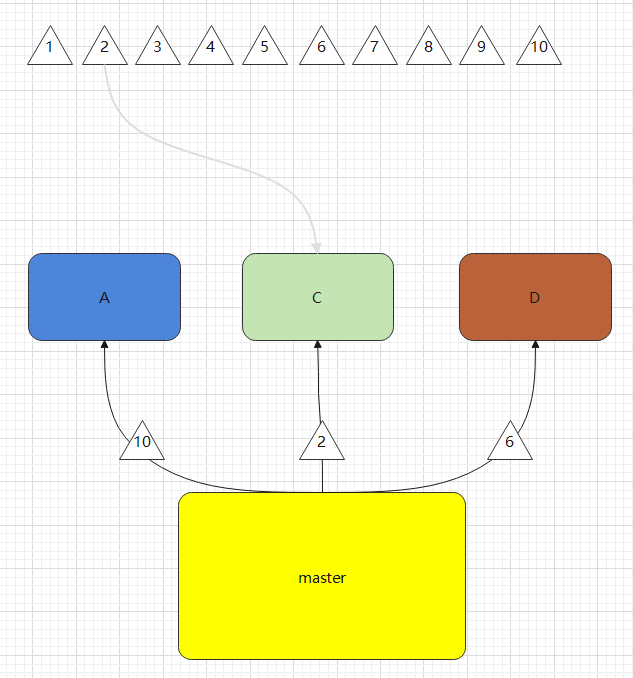
好了,现在原来B库中的数据被重新分配到A,C,D库。
当系统需要取数据的时候,只需要通过参数根据定位算法,
到对应的库中读取即可。
如果现在你以为万事大吉,那可就太早了。
别忘了我们刚刚是聚焦到局部来分析状况的。
当我们目光拉远时,我们发现,
不止是参数为2,6,10的数据被重新分配,
几乎所有的数据都被重新分配了!
因为,
(1*1)%3=1,参数为1的数据落在A库中。
(2*1)%3=2,参数为2的数据落在C库中。
(3*1)%3=0,参数为3的数据落在D库中。
……
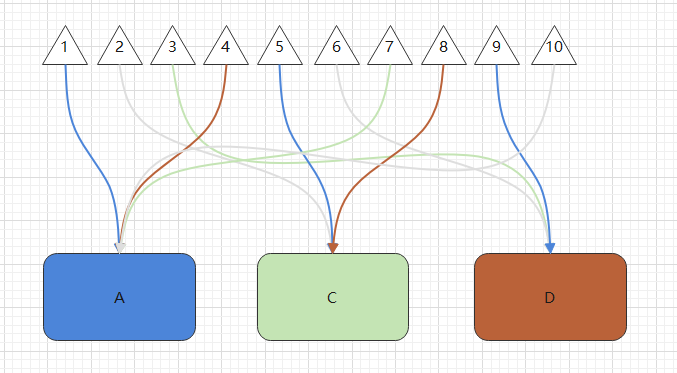
真是糟糕透顶!
原本是想节约提高性能,结果凭空需要浪费这么多计算资源在重新分配数据上。
该怎么办呢?
诶,对,一致性Hash算法要大显身手了!
一致性Hash算法
一致性Hash算法通过一个 Hash 环,巧妙的让影响降到很低。
假设存在一个 Hash 环,它一圈的范围是 0 到 2^32-1,
先对数据库A,B,C和D的标识做 hash 运算,即上面的定位算法,
确定4个库在 Hash 环上的位置,
再通过定位算法将得出参数为1,2,3……9,10共10个数据在 Hash环上的位置,
这边我们不展示过程,只展示结果。
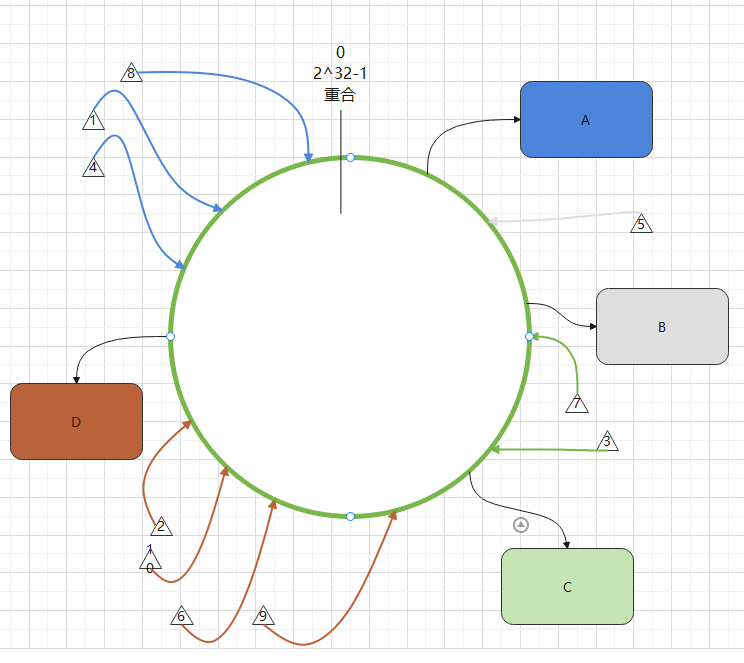
一致性Hash算法规定我们将数据存在定位到的 Hash 环上位置顺时针遇到的第一个节点(数据库)。
即,
参数为1,4和8的数据存在数据库A中,
参数为5的数据存在数据库B中,
参数为3和7的数据存在数据库C中,
参数为2,6,9和10的数据存在数据库D中。
此时,其实我们已经不惧怕数据库宕机的情况了,
假设我们的数据库B又一次失去连接。
会发生什么情况呢?
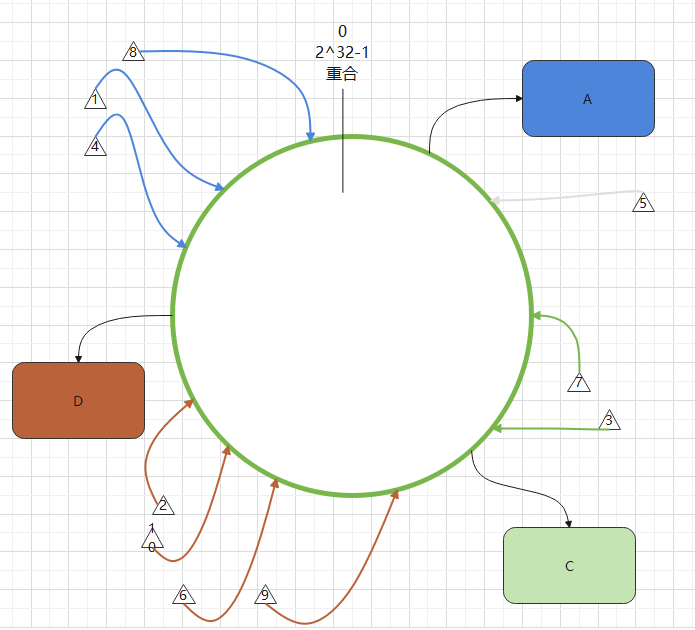
影响十分有限,只有数据库A和B在 Hash 环上的位置之间的数据,才受到了影响。
如图,参数为5的数据,需要重新从主库中复制到数据库C中,以保证系统需要参数为5的数据时可以顺利读取到。
而对于其他参数值的数据,并没有受到影响。
以上描述的是节点减少的情况,实际上在节点增加的时候,
一致性Hash算法依然可以保持大部分节点的稳定,不需要改变。
在这里我不做赘述,但你参考上面,独立思考一下。
一致性 Hash 算法如果只是到这里,实际上还引入了一个新的问题——数据倾斜。
即我们假设数据落在 Hash 环上每个位置的概率是一致的,
但实际上,每个节点覆盖的 Hash 环上的大小并不相等,
甚至可能有几倍的差距。
例如,在上面A,C,D库的基础上,我们添加了一个节点——数据库E。
它的位置如图所示。
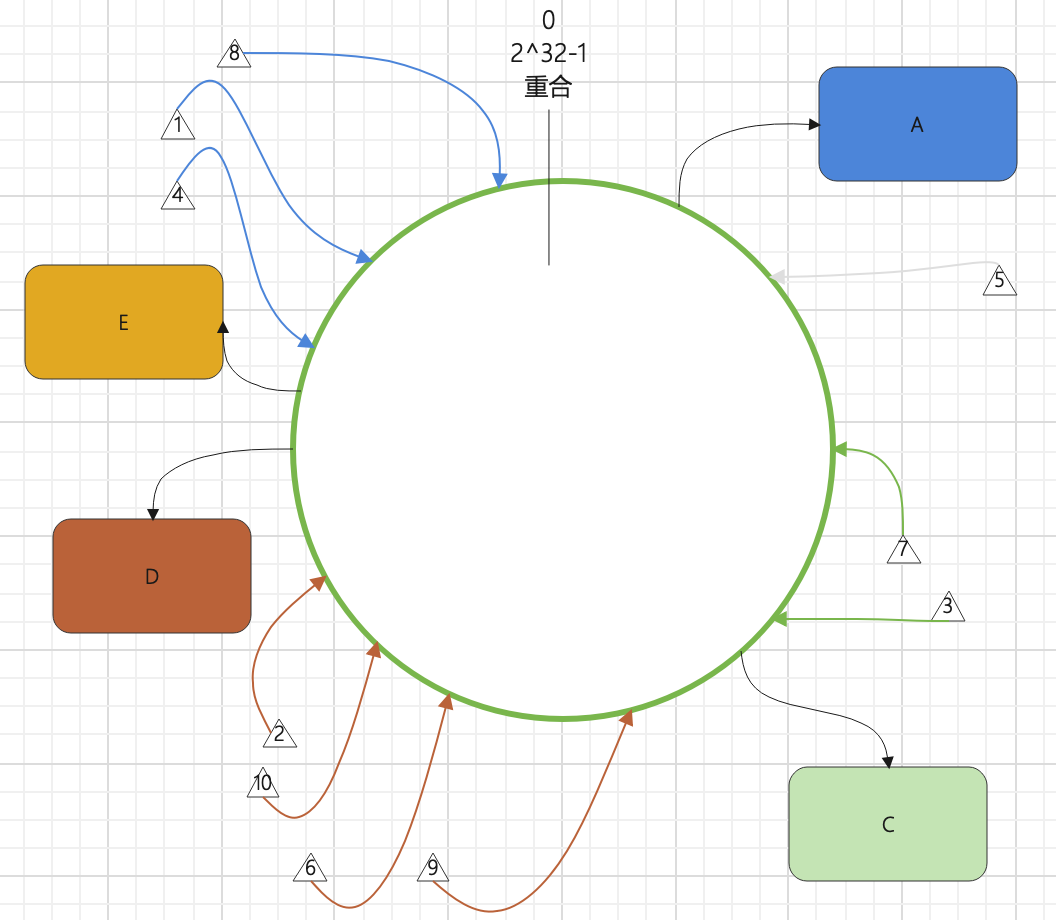
因为它(数据库E)与上一个节点(数据库D)距离太近,导致没有任何一个数据落到它上面,
而正是与他相近特别近的上一个节点(数据库D),却存储了4个数据,
这就是数据倾斜,有些节点承载了很重的任务,有些节点却悠闲悠闲。
虚拟节点
为了解决数据倾斜的问题,我们还需要加入虚拟节点这一策略。
即,将每个数据库都通过定位算法生成几个在 Hash 环上的位置,
每个位置都承担上面节点的功能,
区别在于原来每个数据库对应一个节点,
现在每个数据库会对应若干个节点,
这就是虚拟节点。
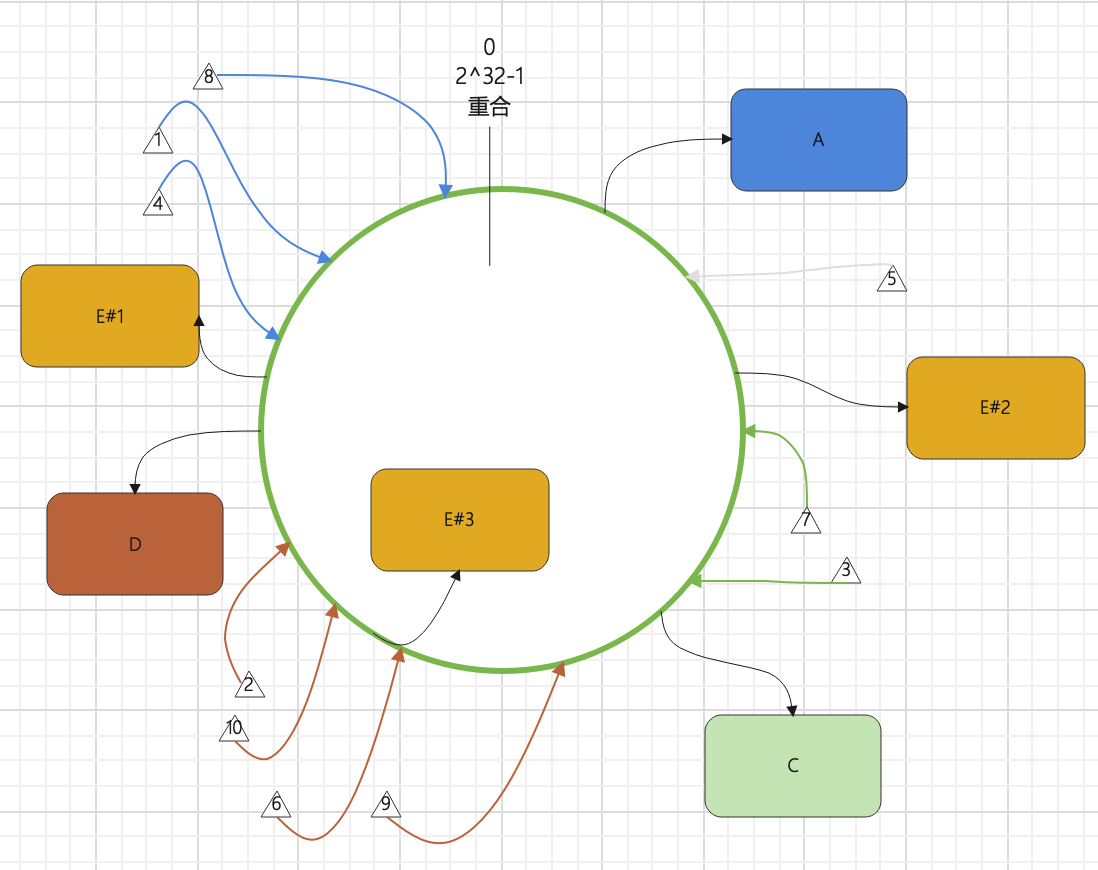
为了避免图过于混乱,这边我标出 E 数据库的 3 个虚拟节点,
可以从图中看出,现在
E#1有 0 个数据,
E#2有 1 个数据(参数为5的数据),
E#3有 2 个数据(参数为6和9的数据)。
而实际上,不管数据定位后归属与E#1、E#2还是E#3,
在实际的数据存储和读取时,都是在数据库 E。
不难发现,在添加了虚拟节点的策略之后,
数据倾斜的情况得到了改善。
这就是完整的一致性Hash算法与虚拟节点啦!
记住,在实际应用中,3个虚拟节点是不够的,你需要更多的虚拟节点,以保证节点的负载更加均衡。